Yesterday I was listening to some music with the Last.fm client, when a song I particularly like started.
As always, I decided to mark the song as “loved” and to tag it with something useful. If you use the Last.fm
client, you know that it suggests the most common tags for the tune you want to tag. Ok, usually the list of
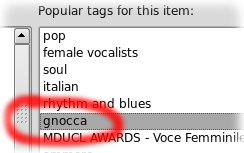
tags includes a lot of stupid words, but this time I was surprised to see the word “gnocca” in the list.
For people not speaking Italian, “gnocca” is a coarse term referring to
the vagina and, by extension, to a sexy girl: it can be translated with “pussy” in the first case and… I
don’t know a suitable translation for the second meaning.
Actually, this is the worst case of tag I’ve ever found, but it’s not the first time I was disappointed
with other user’s tag choice.
As a matter of fact many internet sites that use tags to classify user contents, are showing their
limits. The whole paradigm of user-defined tags, well known with the term folksonomy, is based on three ideas:
- it’s nearly impossible to classify contents inside a tree of categories;
-
associating words (tags) to contents is effective, because the user will remember the world and
then, searching for the tag, he will easily be able to recover the piece of information she
looks for;
-
as a good side effect, if many users tag the same object, the most appropriate tags will emerge
and a big number of users will automatically screen unused or not relevant tags, so that other
people will easily retrieve information.
While I agree with the first statement, the last two are questionable, at least. Sure it’s very
difficult, if not impossible, to arrange a large and heterogeneous set of objects into
a tree-shaped data structure, particularly if the set grows with time and you don’t know in what “direction”
the tree’s growing. Everyone who owns a personal computer and has tried to sort out his or her
“document” folder , now can understand what I mean: there isn’t a hierarchy that fits
to all needs, because many documents can be correctly folded in different places at the same
time.
The proposed solution is to tag documents with a chaotic cloud of words freely
chosen by people, where the only valid criterion seems to be common
sense or a more hazy association of ideas.
My experience is that tagging without a criterion is only another way to lose information. Using a hierarchical tree of directories (or categories) leads the user to lose documents,
because people tend to forget the aspect of the document they have chosen to catalogue it. The same
situation still gets worst with tags: I usually choose as many tags as I think appropriate, in the secret
hope that the large number will help me in the task of searching information later on. The net effect is the
proliferation of synonyms, singular and plural tags
(eg: tool and tools) and completely useless words, because too much generic (eg:
hardware, programming or software), or too much specialistic (eg: xgl or
xen), so that about the 48% of my tags actually label only one document.
Those statistics are based on my personal experience using del.icio.us, one
of the services to which I pay great attention when I choose my tags, because Internet bookmarks are very
important for my job. You can download here the file containing my del.icio.us tags,
ordered by frequency. More than 48% of tags is used only once, and only a 20% is used twice, so I guess
that the most of my tags is completely useless. Not very good, actually.
The lesson here is that cataloguing a large quantity of information is not for free: a
simple and easy way to have tons of documents well ordered, always accessible at any time under your
fingertips, is an utopistic dream.
I think now it’s time to drop buzzwords like “web2.0″ (the parent of all buzzwords) and to pass to some
more serious and structured ideas about information architecture. Since I don’t like to reinvent the wheel
again and again and since I need something to index my documents, I decided to investigate how librarians
organize the knowledge in a big library, following these two ideas:
- the librarian is a very old job, and librarians can boast a thousand-year-old experience;
- I have many documents on my hard disk, and these documents are very different about topics,
media type and relevance, but nothing compared to the Library of Congress or other similar libraries
in the world.
A quick search around led me to some readings and I discovered a whole universe of studies about
information indexing. The most appealing theory I found is the faceted classification, in which multiple trees of “facets” are used to reach information. What are
facets, actually?
A faceted classification system is composed by a number of categories (facets) what represent different
aspects of the items we are going to classify. Each facet (aspect) is explained and developed in a tree of
terms (now to be known as “foci”, or individually, “a focus”). To classify an item, therefore, you apply one or more terms from one or more facets to the item. In this way you
have a multidimensional approach to the items you are indexing.
There are two main criteria developed by librarians to compose faceted classifications:
- the list of facets should represent several aspects of the items to be classified, and should be
“orthogonal”, as much as possible;
- the tree of terms belonging to each facet should present at each node a unique
criterion of division, i.e. the set of children of a node must be a partition of the whole
parent node, so that the hierarchy has no overlapping terms.
Following these two principles the result will be a set of trees in which items are classified, and
consequently several access points from which to start the search. Instead of a tree, the final data
structure resulting from this kind of classification is a DAG (a
directed acyclic graph), which provide a flexible way to organize knowledge, without being chaotic like a “tag cloud”.
An excellent example of faceted classification is the Nobel price winners page, a demo of the Flamenco Project of the Berkeley University: you can navigate through
the various criteria in which Nobels are classified in an intuitive way, with a simple and effective
interface.
Another example of use of facets is the Amazon jewelry page. You can reach the page going to Amazon.com
and looking for “Jewelry and Watches” in the Product Categories menu.
Since I find the idea of facets very interesting, I decided to start a little experiment in this blog:
Wordpress handles trees of categories, so I decided to adapt them and use the whole category system as a
facets system. Is will not be perfect, because there are no facilities to navigate into the DAG, like in the
Flamenco Project, and the reader cannot choose more than one focus at time, but it’s a starting point. If
the result, in a few months, will be better than my experience with del.icio.us tags, I’ll probably start a
software project to handle files on my computer using facets.